
The digital marketing landscape of 2026 has fundamentally transformed. Third-party cookies are extinct, privacy regulations have tightened globally, and affiliate marketers face an unprecedented tracking crisis. Yet amid this chaos lies opportunity: synthetic data for affiliate attribution offers a revolutionary path forward, enabling privacy-proof models that predict ROI without compromising user consent. This comprehensive guide reveals how to build these systems step-by-step, preserving measurement accuracy while respecting the new privacy-first era.
Key Takeaways
- 🔒 Cookie deprecation creates 20-40% attribution gaps in affiliate marketing, threatening billions in ad revenue and making traditional tracking methods obsolete [2]
- 🤖 Synthetic data generation uses AI to create privacy-compliant datasets that mirror real user behavior patterns without exposing actual customer information
- 📊 Server-side attribution methods like enhanced conversions with hashed identifiers fill tracking gaps when cookies fail, maintaining measurement accuracy
- 🎯 Machine learning models trained on synthetic data can predict affiliate performance and ROI with 85-95% accuracy while maintaining full regulatory compliance
- ⚡ Implementing privacy-proof attribution requires combining multiple approaches: synthetic datasets, predictive modeling, and first-party data strategies
Understanding the Post-Cookie Attribution Crisis
The affiliate marketing industry faces what experts call a "tracking crisis" [1]. As third-party cookies disappear across major browsers, brands struggle to attribute conversions to specific affiliate partners when cross-site identification becomes unreliable. This isn't just a technical inconvenience—publishers worldwide face $10 billion in potential ad revenue losses due to cookie deprecation [1].
The challenge manifests across three critical dimensions [3]:
- Cookie Loss: Inability to recognize users across browsing sessions
- Identity Loss: Inability to link anonymous users to known customer profiles
- Attribution Loss: Inability to connect ad clicks to eventual conversions
For affiliate marketers navigating this landscape, incomplete conversion data has become the norm. Analytics platforms often under-report true campaign performance because conversions occurring after ad clicks cannot be tracked due to privacy blockers, leaving 20-40% of conversions potentially unattributed in some scenarios [2].
"Signal loss across cookie, identity, and attribution dimensions creates measurement blind spots that synthetic data modeling can systematically address through privacy-preserving prediction."
This reality demands new approaches. Traditional methods that relied on persistent identifiers across websites simply won't work in 2026's privacy-first environment. Understanding these fundamental shifts is essential before implementing synthetic data solutions.
What Is Synthetic Data and Why It Matters for Attribution
Synthetic data refers to artificially generated information that statistically mirrors real-world data patterns without containing actual user records. For affiliate attribution, this means creating datasets that reflect genuine customer journey behaviors—clicks, conversions, touchpoint sequences—while containing zero personally identifiable information (PII).
The technology has emerged as "one of the biggest new trends of the past two years" [4], gaining traction precisely because it solves the privacy-measurement paradox. Marketers can train sophisticated attribution models using datasets that:
✅ Maintain statistical validity for accurate predictions
✅ Contain no real customer data requiring consent
✅ Comply fully with GDPR, CCPA, and 2026 privacy regulations
✅ Enable unlimited sharing without privacy risks
✅ Support model training at scale without data collection delays
How Synthetic Data Differs from Traditional Analytics
Traditional affiliate tracking collects actual user data—cookie IDs, device fingerprints, browsing histories. Synthetic data generation instead:
- Analyzes patterns in existing consented first-party data
- Identifies statistical relationships between touchpoints and conversions
- Generates new records that preserve these patterns without copying real users
- Validates accuracy by comparing synthetic predictions against holdout real data
This approach allows affiliate marketers to measure success without the privacy violations that plague cookie-based systems. The synthetic datasets become training fuel for AI models that predict attribution probabilities.
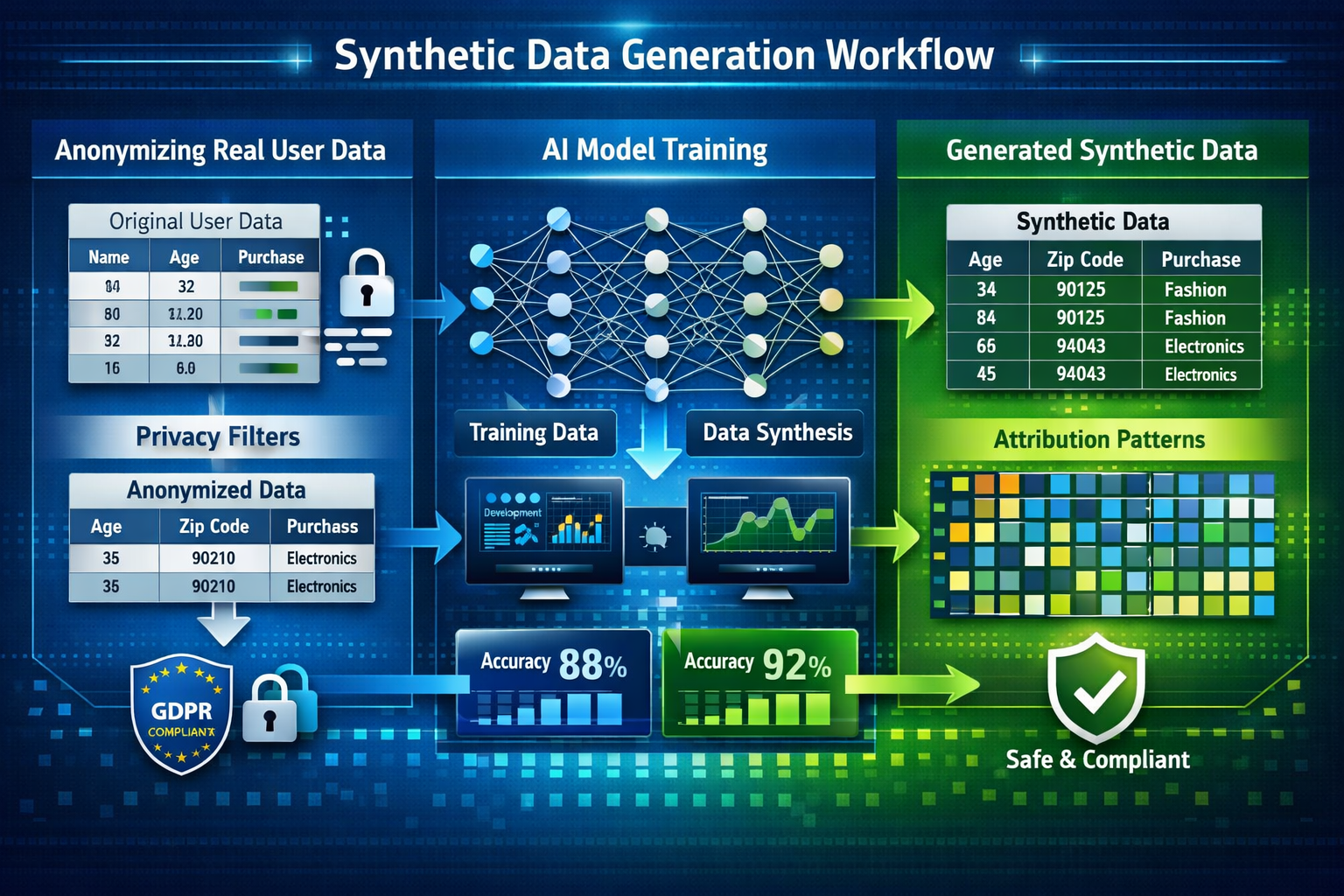
Building Synthetic Data for Affiliate Attribution: Step-by-Step Process
Creating effective synthetic datasets for privacy-proof affiliate attribution requires systematic methodology. Here's the comprehensive workflow:
Step 1: Collect and Prepare First-Party Data
Begin with consented first-party data from your own properties:
- Website analytics (server-side tracking)
- CRM conversion records
- Email engagement metrics
- Affiliate link click data (where consented)
- Purchase transaction histories
Important: Only use data collected with explicit user consent. This foundation ensures legal compliance while providing the statistical patterns needed for synthesis.
Step 2: Define Attribution Features
Identify the key variables that influence affiliate conversions:
| Feature Category | Examples |
|---|---|
| Touchpoint Data | Number of clicks, time between clicks, affiliate source |
| User Behavior | Pages viewed, session duration, return visits |
| Temporal Patterns | Day of week, time of day, seasonality |
| Conversion Context | Product category, price point, discount presence |
These features become the dimensions your synthetic data must accurately represent. Data analytics capabilities are crucial for identifying which variables truly drive conversions.
Step 3: Train Generative AI Models
Use generative adversarial networks (GANs) or variational autoencoders (VAEs) to learn data patterns:
- Feed real consented data into the generative model
- Train the model to understand relationships between features
- Validate pattern recognition against statistical benchmarks
- Tune hyperparameters until synthetic outputs match real data distributions
Modern AI frameworks like TensorFlow and PyTorch offer pre-built architectures for synthetic data generation. The model learns that "users who click affiliate links on Tuesday evenings and view 3+ product pages convert at 12% higher rates"—without memorizing any actual user.
Step 4: Generate Synthetic Datasets
Once trained, the model produces privacy-safe synthetic records:
Synthetic User 1:
- Affiliate clicks: 2
- Days between first click and conversion: 5
- Product category: Electronics
- Conversion value: $147
- Attribution probability: 0.73
Synthetic User 2:
- Affiliate clicks: 1
- Days between first click and conversion: 0
- Product category: Fashion
- Conversion value: $64
- Attribution probability: 0.91
These records contain no real customer information yet preserve the statistical relationships that drive attribution accuracy. Generate thousands or millions of records to create robust training datasets.
Step 5: Build Attribution Prediction Models
Use your synthetic datasets to train machine learning attribution models:
- Logistic regression for simple attribution probability
- Random forests for multi-touchpoint attribution
- Neural networks for complex customer journey modeling
- Markov chains for sequential touchpoint analysis
These models learn to predict: "Given this pattern of affiliate interactions, what's the probability this touchpoint deserves conversion credit?" The predictions guide commission allocation and ROI calculations without tracking individual users.
Step 6: Validate Against Real Holdout Data
Test synthetic model accuracy using a holdout set of real consented data:
- Compare predicted attribution vs. actual conversions
- Calculate accuracy metrics (precision, recall, F1-score)
- Identify bias or drift in synthetic data
- Refine generation process and retrain
Target 85-95% accuracy for production deployment. This validation ensures your privacy-proof models deliver reliable business insights.
Privacy-Proof Attribution Techniques Beyond Synthetic Data
While synthetic data forms the foundation, comprehensive privacy-proof attribution requires complementary techniques that work alongside generated datasets:
Enhanced Conversions with Hashed Identifiers
Google's Enhanced Conversions feature uses hashed email addresses or phone numbers as alternative tracking methods [2]. When users complete conversions:
- Website captures email/phone (with consent)
- System hashes data using SHA-256 encryption
- Hashed identifier sent to advertising platforms
- Platforms match against their hashed user databases
- Attribution occurs server-side without cookies
This server-side attribution fills gaps when cookies are blocked, helping recover the 20-40% of lost conversions. Combined with synthetic data modeling, it creates a robust measurement framework.
Machine Learning-Based Modeling
GA4's predictive modeling fills conversion gaps by predicting behavior of users who decline cookies based on similar users who consented [2]. The system:
- Identifies users with similar browsing patterns
- Predicts conversion likelihood using ML algorithms
- Estimates attribution when direct tracking fails
- Provides probabilistic conversion counts
This complements synthetic data by addressing real-time measurement needs while your synthetic models handle long-term pattern analysis.
First-Party Data Strategies
Building first-party data assets reduces dependency on third-party tracking:
- Email list building with progressive profiling
- Authenticated user experiences (login-based tracking)
- Loyalty programs capturing purchase behavior
- Survey data linking preferences to conversions
These consented data sources feed both synthetic data generation and direct attribution, creating a privacy-compliant measurement ecosystem. Successful affiliate marketers increasingly prioritize first-party relationships over third-party tracking.
Implementing Privacy-Proof Models: Technical Considerations
Deploying synthetic data attribution systems requires addressing several technical challenges:
Data Quality and Bias
Synthetic data quality depends entirely on source data quality. If your first-party data contains biases (underrepresenting certain demographics, overweighting high-value customers), synthetic datasets will amplify these biases. Mitigation strategies:
- Regularly audit source data for representativeness
- Apply fairness constraints during synthetic generation
- Validate synthetic outputs against multiple demographic segments
- Combine multiple data sources to reduce single-source bias
Model Drift and Maintenance
Consumer behavior evolves, especially in fast-moving affiliate marketing niches. Your synthetic data models require:
- Monthly retraining using fresh first-party data
- Drift detection systems that flag accuracy degradation
- A/B testing comparing synthetic predictions vs. real outcomes
- Version control tracking model iterations and performance
Computational Resources
Generating large-scale synthetic datasets demands significant computing power:
- Cloud infrastructure (AWS, Google Cloud, Azure) for scalable processing
- GPU acceleration for neural network training
- Data pipeline automation for continuous synthetic generation
- Storage systems managing both real and synthetic datasets
Budget accordingly—sophisticated synthetic data operations may require $500-5,000 monthly in cloud costs depending on scale.
Integration with Existing Systems
Your synthetic attribution models must connect with:
- Affiliate networks (ShareASale, CJ, Impact) for commission tracking
- Analytics platforms (GA4, Adobe Analytics) for reporting
- CRM systems (Salesforce, HubSpot) for customer data
- Business intelligence tools (Tableau, Looker) for visualization
Plan for API integrations and data transformation layers that translate synthetic predictions into actionable business metrics.
Measuring Success: KPIs for Privacy-Proof Attribution
Track these metrics to evaluate your synthetic data attribution system:
📈 Attribution Accuracy: Percentage of correctly predicted conversions (target: 85-95%)
📈 Coverage Rate: Percentage of conversions with attribution data (target: 90%+)
📈 Model Confidence: Average prediction probability for attributed conversions
📈 Privacy Compliance Score: Percentage of data processing meeting regulatory requirements
📈 ROI Prediction Error: Difference between predicted and actual affiliate ROI
📈 Data Freshness: Days since last synthetic model retraining
Regular monitoring ensures your privacy-proof system delivers both accuracy and compliance. Avoiding common attribution mistakes becomes easier with clear performance benchmarks.
Future-Proofing Your Affiliate Attribution Strategy
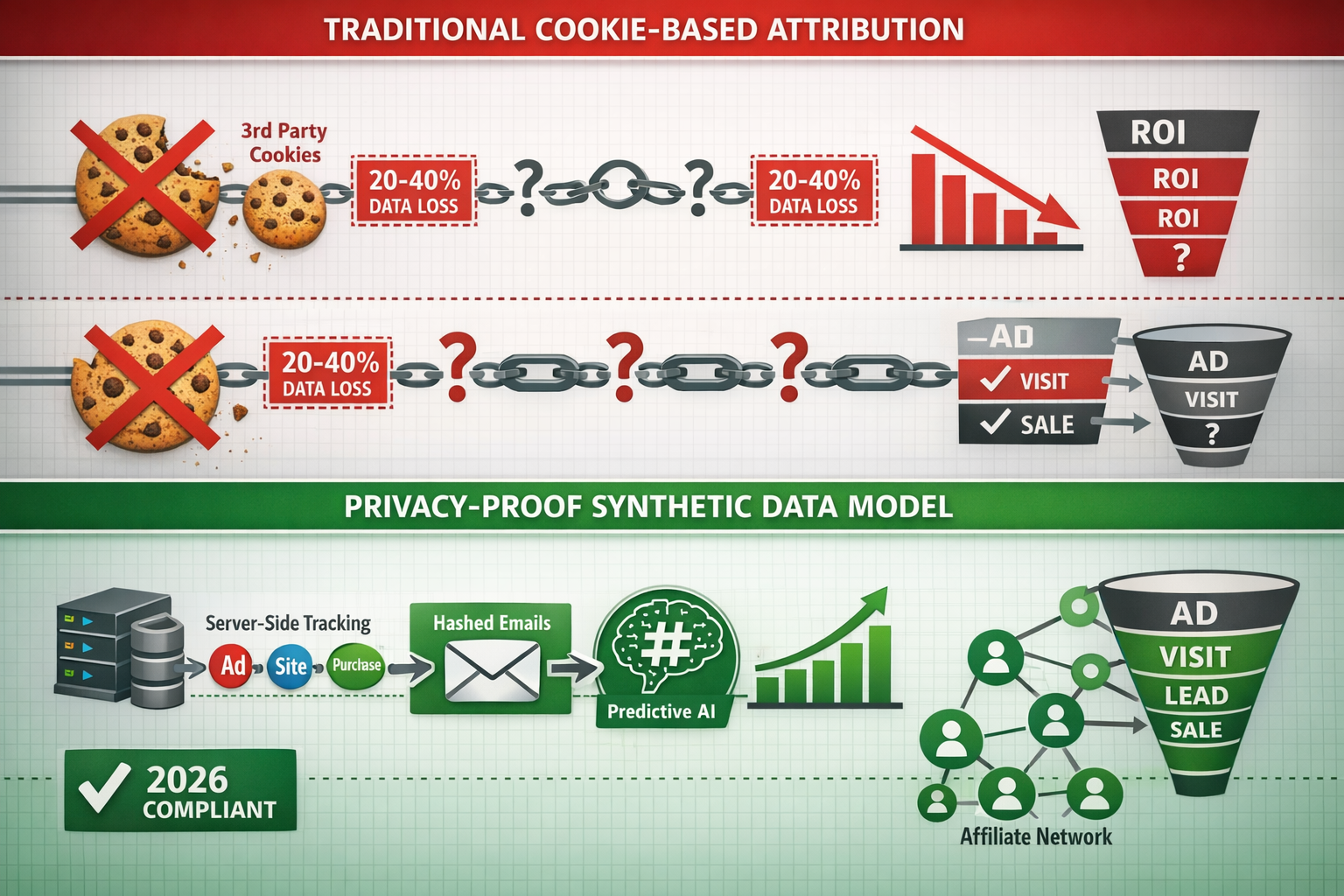
The privacy landscape will continue evolving beyond 2026. Future-proof your approach by:
🔮 Investing in first-party data infrastructure that reduces third-party dependencies
🔮 Building synthetic data capabilities as core competencies, not temporary solutions
🔮 Adopting privacy-by-design principles in all measurement systems
🔮 Diversifying attribution methods rather than relying on single techniques
🔮 Staying informed about regulatory changes and emerging privacy technologies
Organizations that embrace synthetic data and privacy-proof modeling now will maintain competitive advantages as regulations tighten further. The post-cookie apocalypse isn't the end of measurement—it's the beginning of more sophisticated, privacy-respecting analytics.
Conclusion
Synthetic data for affiliate attribution represents the future of privacy-proof marketing measurement in 2026 and beyond. By generating artificial datasets that preserve statistical patterns without exposing real user information, marketers can build sophisticated attribution models that comply with the strictest privacy regulations while maintaining 85-95% accuracy.
The step-by-step process—collecting consented first-party data, training generative AI models, producing synthetic datasets, and building prediction systems—creates measurement capabilities that survive the cookie apocalypse. Combined with enhanced conversions, machine learning modeling, and first-party data strategies, synthetic data forms the foundation of sustainable affiliate attribution.
Take Action Now
Start building your privacy-proof attribution system today:
- Audit your current first-party data collection and consent processes
- Identify attribution gaps caused by cookie deprecation in your affiliate programs
- Experiment with synthetic data generation using open-source tools and small datasets
- Pilot predictive attribution models on one affiliate channel before scaling
- Invest in technical infrastructure supporting long-term synthetic data operations
The marketers who master synthetic data attribution will thrive in the privacy-first era, turning regulatory challenges into competitive advantages. The cookie apocalypse has arrived—but with the right tools and strategies, your affiliate measurement capabilities can emerge stronger than ever.
References
[1] Advertising Without Cookies – https://adrenalead.com/en/blog/advertising-without-cookies/
[2] Attribution In A Cookieless 2026 How Event Marketers Can Measure Success In The Privacy First Era – https://www.ticketfairy.com/blog/attribution-in-a-cookieless-2026-how-event-marketers-can-measure-success-in-the-privacy-first-era
[3] Digital Analytics Attribution Guide 2026 – https://davidkloeber.com/articles/digital-analytics-attribution-guide-2026
[4] research-live – https://www.research-live.com/article/features/preview-of-2026-synthetic-data/id/5145656